Localizing Moments in Long Video via Multimodal Guidance
Abstract
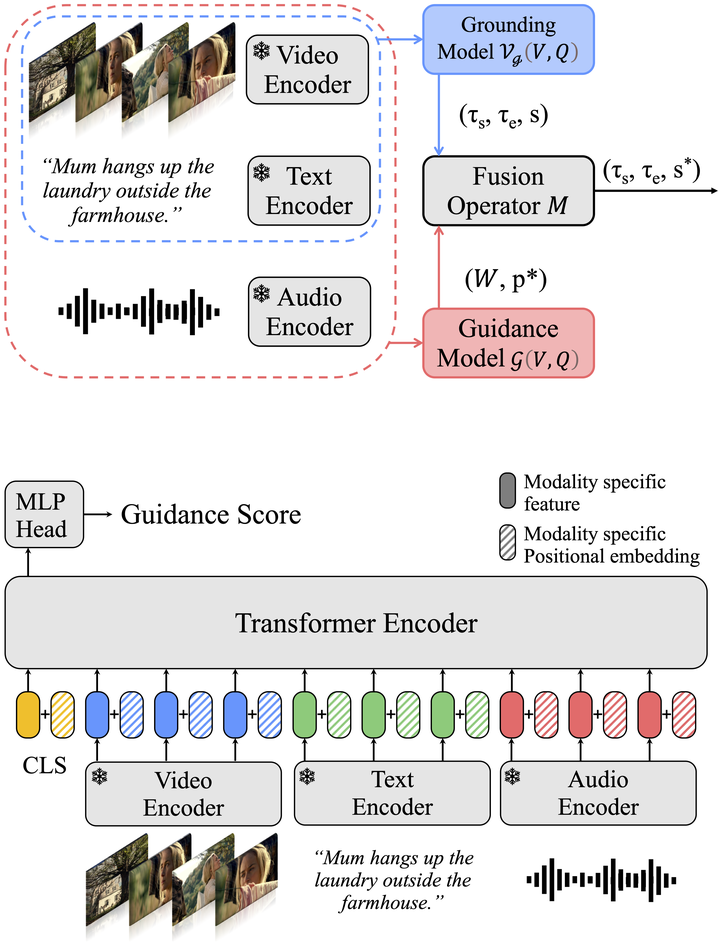
The recent introduction of the large-scale, long-form MAD and Ego4D datasets has enabled researchers to investigate the performance of current state-of-the-art methods for video grounding in the long-form setup, with interesting findings: current grounding methods alone fail at tackling this challenging task and setup due to their inability to process long video sequences. In this paper, we propose a method for improving the performance of natural language grounding in long videos by identifying and pruning out non-describable windows. We design a guided grounding framework consisting of a Guidance Model and a base grounding model. The Guidance Model emphasizes describable windows, while the base grounding model analyzes short temporal windows to determine which segments accurately match a given language query. We offer two designs for the Guidance Model: Query-Agnostic and Query-Dependent, which balance efficiency and accuracy. Experiments demonstrate that our proposed method outperforms state-of-the-art models by 4.1% in MAD and 4.52% in Ego4D (NLQ), respectively.
BibTex
@inproceedings{barrios2023localizing,
title={Localizing moments in long video via multimodal guidance},
author={Barrios, Wayner and Soldan, Mattia and Ceballos-Arroyo, Alberto Mario and Heilbron, Fabian Caba and Ghanem, Bernard},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages={13667--13678},
year={2023}
}
Mattia Soldan
PhD Candidate - Electrical and Computer Engineering
My research interests are settled at the intersection between Computer Vision and Natural Language Processing.